OpenCV is a free library for computer vision containing an extensive number of algorithms related to computer vision problems. In its native form, it is a C/C++ library, although, ports to other languages (e.g. Python) are available. Good introductions to the computer vision field with OpenCV are offered in the official documentation (look out for the tutorials) or in the corresponding book written by the authors of the library itself. Getting started is pretty easy since pre-built binaries are available. Nevertheless, in this article, I want to describe how to get your own build of the OpenCV library.
So, why the effort of creating an own build? Well, while the official builds are great to begin, they lack unfortunately of the debug information from the build process. Especially, they do not contain the PDB files created during the build process. These are especially useful because of the mapping between the binaries of the library and the original source code. Usually, when you link your code against some library (e.g. statically linking against a .lib during compile time or including a .dll during runtime on Windows) you link only against the compiled machine code. This is great for performance but not so great if errors occur and you want to look up in the original source code the identify the problem. This is where PDB files help out. They contain (among others) the mapping between the machine code and the original source line which produced the machine code. With this information, it is possible to step through the original source code during debugging in Visual Studio. This is useful for all libraries, but especially with OpenCV since they like to use assertions (which is great) and so it might happen that your application crashes with some cryptic message which shows the original failing code. The assertion code is much more useful when you see the surrounding context (including stack trace, variables, etc.) which produced it.
That being said, I want now give an instruction of how I create my builds including debug information. Unfortunately, PDB files contain only the absolute path to the original source code by default. Even though it seems that this can be changed later in Visual Studio (I have never tested it myself), it would be advisable to use the same paths as in the following build instruction in order to get the source mapping working out of the box. Another caveat is that Visual Studio has a predefined mechanism where to search for PDB files which belong to a loaded DLL. Even though it should look in the directory of the DLL itself, this did not work for me. But it does look in the folder of the original location of the DLL (e.g. where the DLL is first stored to)1. Therefore, is important to make sure the DLL files are stored directly in the installation directory. Again, this is also something you can change during debugging in Visual Studio itself but I would rather prefer an out of the box solution.
Building
- First, get a copy of the latest master branch. I would recommend to store also the latest commit ID and save it in an appropriate text file (
version.txt) for future reference - Create the following folder structure (I downloaded the sources as zip file)
C:/OpenCV |-- build |-- cmake_build `-- sources |-- opencv-master |-- opencv-master.zip `-- version.txtbuildfolder is the installation directory where the created binaries will be stored.cmake_buildcontains all the files created and needed for building. The foldersources/opencv-mastercontains the source code from the git repository (which is also the folder referenced by the PDB files) - Open cmake-gui.exe and set the paths

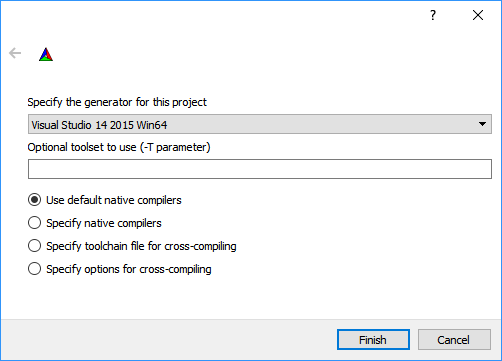
- Press Configure. A window opens where you need to specify the target toolset (i.e. the compiler toolset of the Visual Studio version). In my case, I build with Visual Studio 2015 for the x64 architecture, therefore, selecting Visual Studio 14 2015 Win64
- After this step, you see all the options (which are all read) you can configure your own build process. I changed only the following entries and left the rest on default
BUILD_DOCS --> OFF // I don't need the documentation since I look it up online anyway (or look directly in the header files) BUILD_EXAMPLES --> ON // Examples are quite useful to get a first impression of an algorithm BUILD_opencv_world --> ON // This builds a unified DLL containing the machine code for all modules. This is easier for deploying since only one file needs to be located alongside the executable, but also increases the size of the application directory due to the (unnecessary) code of unused modules. Personally, I am currently fine with only one DLL ENABLE_AVX --> ON // This and the following entries enable the use of special processor instructions which should speed up performance. But make sure your processor supports them! ENABLE_AVX2 --> ON ENABLE_FMA3 --> ON ENABLE_SSE41 --> ON ENABLE_SSE42 --> ON ENABLE_SSSE3 --> ON WITH_OPENCL_SVM --> ON // This enables the use of shared virtual memory in OpenCL programming. Not sure if I really need that but sounds great to use it^^ CMAKE_INSTALL_PREFIX --> C:/OpenCV/build // This is actually very important. It specifies where the resulting binaries should be installed to after compilation. Without this option, an install folder would be created inside the cmake_build folder. But since the resulting binaries should be placed inside the build folder, this would require to manually copy them. And this again breaks the default PDB loading mechanism described above - Press Configure again. If everything went well, no red entries should be left
- Now press Generate which places the Visual Studio solutions to the
cmake_buildfolder - Open the solution
cmake_build/OpenCV.slmwith Visual Studio (wait until the analysation steps are done) - Make sure that the solution ALL_BUILD is selected as the main project and build it twice, once in release and once in debug mode
- If the build step was successful, mark the solution INSTALL as the main project and build it also in release and debug mode (no re-build necessary). This step fills the
buildfolder - Copy the file
cmake_build\bin\Debug\opencv_world320d.pdbto the folderbuild\x64\vc14\binso that you get the mapping to the OpenCV source files - Copy the test module's files from
cmake_build\lib\Debug\opencv_ts320d.libandcmake_build\lib\Release\opencv_ts320.libto the folderbuild\x64\vc14\lib. They seem to be necessary but not copied by the installation step itself for some reasons - If you like, you could archive the
cmake_buildfolder and delete it afterwards to save space on the disk. I would not delete it completely since you may need some of the build files again in the future
Configuring
If everything proceeded without errors, you have now your own build of the OpenCV library. But to use it, you first should configure your system properly. Including a library involves two steps:
- You have to put the header files to the project's include directory so that you can access the interface of the library
- And you must link against the compiled code. Since I want to link dynamically using the produced DLL files, this step is comprised of two additional steps
- The compiled library code resides in DLL files. In order to load the contained code during runtime, the libraries must be available to the application. Windows searches for libraries in the directory of the application itself and (if the DLL is not found) in all directories which are set in the
PATHvariable. Because I do not want to copy the DLL files to each application's directory (including the OpenCV examples), I decide for thePATHvariable approach. In this case, all applications on the system use the same DLL. But this also means that thePATHvariable needs to be adjusted - Creating a DLL involves also the creation of a corresponding LIB file. This is not the same as the LIB file which would be produced when linking completely statically to the library. It is much smaller and contains only the information needed to load the corresponding DLL file during runtime. But, the application which depends on a DLL file must link statically against the produced LIB file in order to properly resolve the dependency during runtime. So, the library directory and the library dependency needs to be added to the application
- The compiled library code resides in DLL files. In order to load the contained code during runtime, the libraries must be available to the application. Windows searches for libraries in the directory of the application itself and (if the DLL is not found) in all directories which are set in the
To simplify the steps, it is advisable to work with an additional system variable which points to the build directory. In the build configuration, we can then refer to the variable instead of the concrete hardcoded path. If the path to the build directory needs to be changed ever again in the future, only the system variable needs to be adjusted. To create a system variable named OPENCV_DIR which points to the directory C:/OpenCV/build open a command prompt with administrative privileges and run the following command
setx -m OPENCV_DIR C:\OpenCV\build
Next, we want to use this system variable to extend the PATH variable with an additional entry pointing to the folder containing OpenCV's DLL files. They are located in C:/OpenCV/build/x64/vc14/bin (x64 architecture and built with Visual Studio 2015), so the following command will do the job (re-login to Windows or kill and re-create explorer.exe in order to apply the changes)
setx PATH "%PATH%;%%OPENCV_DIR%%\x64\vc14\bin" /M
The settings for the include directory and static library linking are project specific and must be set for each project individually. To simplify the process in Visual Studio, I would suggest using a property sheet. This is an XML file which contains the necessary settings for the compiler and linker. They can then be easily added to Visual Studio in the Project Manager and all settings are configured.
In our case, the following property sheet would be appropriate:
<?xml version="1.0" encoding="utf-8"?>
<Project ToolsVersion="4.0" xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
<ImportGroup Label="PropertySheets" />
<PropertyGroup Label="UserMacros" />
<ItemDefinitionGroup>
<!-- Include directory -->
<ClCompile>
<AdditionalIncludeDirectories>$(OPENCV_DIR)\include;%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
</ClCompile>
<Link>
<!-- Library directory -->
<AdditionalLibraryDirectories Condition="'$(PlatformToolset)'=='v120'">$(OPENCV_DIR)\$(Platform)\vc12\lib;%(AdditionalLibraryDirectories)</AdditionalLibraryDirectories>
<AdditionalLibraryDirectories Condition="'$(PlatformToolset)'=='v140'">$(OPENCV_DIR)\$(Platform)\vc14\lib;%(AdditionalLibraryDirectories)</AdditionalLibraryDirectories>
<AdditionalLibraryDirectories Condition="'$(PlatformToolset)'=='v141'">$(OPENCV_DIR)\$(Platform)\vc141\lib;%(AdditionalLibraryDirectories)</AdditionalLibraryDirectories>
<!-- Library files -->
<AdditionalDependencies Condition="'$(Configuration)'=='Debug'">opencv_ts320d.lib;opencv_world320d.lib;%(AdditionalDependencies)</AdditionalDependencies>
<AdditionalDependencies Condition="'$(Configuration)'=='Release'">opencv_ts320.lib;opencv_world320.lib;%(AdditionalDependencies)</AdditionalDependencies>
</Link>
</ItemDefinitionGroup>
</Project>
As you can see, it is also possible to reference the OPENCV_DIR system variable. Conditions are used to check for different toolsets (i.e. Visual Studio versions) respectively the current build configuration. $(Platform) evaluates to the target architecture name, e.g. x64 or x862.
The AdditionalIncludeDirectories tag adds an additional path for the include directory which makes sure the compiler knows where to locate OpenCV's header files. This lets you write something like #include <opencv2/core.hpp> in your code. AdditionalLibraryDirectories adds an additional directory to linker where it searches for library files which are references in the library files section by the AdditionalDependencies tag.
You now have everything you need for your first project in OpenCV. If you do not want to write your own, you can also check out my test project for this blog article on GitHub. I attach also the binaries from my build process. If you make sure to keep the directory structure from above, you can use OpenCV with source mapping out of the box.
List of attached files:
- OpenCVBuild_OpenCV.props (Property sheet containing the configurations needed for each project)
- OpenCVBuild_OpenCVBinaries.7z (Binaries produced by my build process. I created them using the master branch from 2017-03-15 (commit 27cf6e549e6051533778dd39b4b050a6d08d735b) and the above settings.)