Suppose you have some data and want to get a feeling about the underlying probability distribution which produced them. Unfortunately, you don't have any further information like the type of distribution (\(t\)-distribution, Poisson, etc.) or its parameters (mean, variance, etc.). Further, assuming a normal distribution does not seem to be the right thing. This situation is quite common in reality and the good news is that there are some helpful techniques. One is known as kernel density estimation (also known as Parzen window density estimation or Parzen-Rosenblatt window method). This article is dedicated to this technique and tries to convey the basics to understand it.
Parzen window is a so-called non-parametric estimation method since we don't even know the type of the underlying distribution. In contrast, when we estimate the PDF1 \(\hat{p}(x)\) in a parametric way, we know (or assume) the type of the PDF (e.g. a normal distribution) and only have to estimate the parameters of the assumed distribution. But, in our case, we really know nothing and hence need to find a different approach which is not based on finding the best-suited parameters. Further, we assume continuous data and hence work with densities instead of probabilities.2
Let's start by formulating what we have and what we want. Given is a set of \(N\) data points \(X = (x_1, x_2, \ldots, x_N)\) and our goal is to find a PDF which satisfies the following conditions:
- The PDF should resemble the data. This means that the general structure of the data should still be visible. We don't require an exact mapping but groups in the dataset should also be noticeable as high-density values in the PDF.
- We are interested in a smooth representation of the PDF. Naturally, \(X\) contains only a discrete list of points but the underlying distribution is most likely continuous. This should be covered by the PDF as well. More importantly, we want something better than a simple step function as offered by a histogram (even though histograms will be the starting point of our discussion). Hence, the PDF should approximate the distribution beyond the evidence from the data points.
- The last point is already implied by the word PDF itself: we want the PDF to be valid. Mathematically, the most important properties which the estimation \(\hat{p}(x)\) must obey are \begin{equation} \label{eq:ParzenWindow_PDFConstraints} \int_{-\infty}^{\infty} \! \hat{p}(x) \, \mathrm{d}x = 1 \quad \text{and} \quad \hat{p}(x) \geq 0. \end{equation} That is, the PDF should integrate up to 1 and every density value is non-negative.
The rest of this article is structured as follows: we are going to start with one-dimensional data and histograms. Even though this is not intended to be a full introduction to histograms, it is good starting point for our discussion. We are going to face the problems of classical histograms and the solution ends indeed in the Parzen window estimator. We are looking at the definition of the estimator and try to get some intuition about its components and parameters. It is also possible to reach the estimator from a different way, namely from the signal theory, by using convolution and we are going to take a look at this, too. In the last part, we are going to generalize the estimator to the multi-dimensional case and provide an example in 2D.
It starts with histograms
Histograms are a very easy way to get information about the distribution of the data. They show us how often certain data points occur in the whole dataset. A common example is an image histogram which shows the distribution of the intensity values in an image. In this case, we can simply count how often each of the 256 intensity values occurs and draw a line for each intensity value with the height corresponding to the number of times that intensity value is present in the image.
Another nice property of the histogram is that it can be scaled to be a valid discrete probability distribution itself (though, not a PDF yet3). This means we reduce the height of each line so that the total sum is 1. In the case of a image histogram, we can simply make the count a relative frequency by dividing by the total number of pixels and we end up with a valid distribution. To make this more concrete, let \(b_i\) denote the number of pixels with intensity \(i\) and \(N\) the total number of pixels in the image so that we can calculate the height of each line as
\begin{equation} \label{eq:ParzenWindow_ImageHistogram} \hat{p}_i = \frac{b_i}{N}. \end{equation}\(\hat{p}_i\) is then an estimate of the probability of the \(i\)-th intensity value (the relative frequency).
An image histogram is a very simple example because we have only a finite set of values to deal with. In other cases, the border values (e.g. 0 and 255 in the image example) are not so clear. What is more, the values might not even be discrete. If every value \(x \in \mathbb{R}\) is imaginable, the histogram is not very interesting since most of the values will probably occur only once. E.g. if we had the values 0.1, 0.11 and 0.112, they would end up as three lines in our histogram.
Obviously, we need something more sophisticated. Instead of counting the occurrences of each possible value, we collect them in so-called bins. Each bin has a certain width and we assign the values to whichever bin they are falling into. Instead of lines, we now draw bars and the height of each bar is proportional to the number of values which had been falling into the bin. For simplicity, we are assuming that each bin has the same width. Note, however, that this is not necessarily a requirement.
Let's redefine \(b_i\) to denote the number of values which are falling into the \(i\)-th bin. Can we still use \eqref{eq:ParzenWindow_ImageHistogram} to calculate the height of each bar when the requirement is now to obtain a valid PDF? No, we can't since the histogram estimate \(\hat{p}(x)\) would violate the first constraint of \eqref{eq:ParzenWindow_PDFConstraints}, i.e. the area of all bars does not integrate up to 1. This is due to the binning where we effectively expand each line horizontally to the bin width, i.e. we make it a rectangle. This influences the occupied area and we need some kind of compensation. But, the solution is very simple: we just scale the height by the bin width4 \(h > 0\)
\begin{equation} \label{eq:ParzenWindow_Histogram} \hat{p}(x) = \begin{cases} \frac{1}{h} \cdot \frac{b_i}{N} & \text{if \(x\) falls into the bin \(b_i\)} \\ 0 & \text{else} \\ \end{cases} \end{equation}Let's create a small example which we can also use later when we dive into the Parzen window approach. We consider a short data set \(X\) consisting only of four points (or more precisely: values)
\begin{equation} \label{eq:ParzenWindow_ExampleData} X = \begin{pmatrix} 1 \\ 1.5 \\ 3 \\ 5 \\ \end{pmatrix}. \end{equation}Suppose, we want to create a histogram with bins of width \(h=2\). The first question is: where do we start binning, i.e. what is the left coordinate of the first bin? 1? 0? -42? This is actually application-specific since sometimes we have a natural range where it could be valid to start e.g. with 0. In this case, however, there is no application context behind the data so let's just start at \(\min(X) = 1\). With this approach, we can cover the complete dataset with three bins (\(B_i\) denotes the range of the \(i\)-th bin)
\begin{equation*} B_1 = [1;3[, B_2 = [3;5[ \quad \text{and} \quad B_3 = [5;7]. \end{equation*}The first two data points are falling into \(B_1\) and the other two in \(B_2\) and \(B_3\). We can calculate the heights of the bins according to \eqref{eq:ParzenWindow_Histogram} as
\begin{equation*} \hat{p}(B_1) = \frac{1}{2} \cdot \frac{2}{4} = 0.25 \quad \text{and} \quad \hat{p}(B_2) = \hat{p}(B_3) = \frac{1}{2} \cdot \frac{1}{4} = 0.125. \end{equation*}It is easy to see that this sums indeed up to \(2 \cdot 0.25 + 2 \cdot 2 \cdot 0.125 = 1\). The following figure shows a graphical representation of the histogram.

So, why do we need something else when we can already obtain a valid PDF via the histogram method? The problem is that histograms provide only a rough representation of the underlying distribution. And as you can see from the last example, \(\hat{p}(x)\) results only in a step function and usually we want something smoother. This is where the Parzen window estimator enters the field.
From histograms to the Parzen window estimator
Our goal is to improve the histogram method by finding a function which is smoother but still a valid PDF. The general idea of the Parzen window estimator is to use multiple so-called kernel functions and place them at the positions of the data points. We are superposing all of these kernels and scale the result to our needs. The resulting function from this process is our PDF. We implement this idea by replacing the cardinality of the bins \(b_i\) in \eqref{eq:ParzenWindow_Histogram} with something more sophisticated (still for the one-dimensional case):
Let \(X = (x_1, x_2, \ldots, x_N) \in \mathbb{R}^N\) be the column vector containing the data points \(x_i \in \mathbb{R}\). Then, we can use the Parzen window estimator
\begin{equation} \label{eq:ParzenWindow_KernelDensity} \hat{p}(x) = {\color{Orange}\frac{1}{h \cdot N}} \cdot {\color{Aquamarine}\sum_{i=1}^N} {\color{Red}K}\left( \frac{{\color{Mahogany}x_i -} x}{{\color{LimeGreen}h}} \right) \end{equation}to retrieve a valid PDF which returns the probability density for an arbitrary \(x\) value. The kernels \(K(x)\) have to be valid PDFs and are parametrized by the side length \(h \in \mathbb{R}^+\).
To calculate the density for an arbitrary \(x\) value, we now need to iterate over the complete dataset and sum up the result of the evaluated kernel functions \(K(x)\). The nice thing is that \(\hat{p}(x)\) inherits the properties of the kernel functions. If \(K(x)\) is smooth, \(\hat{p}(x)\) tends to be smooth as well. That is, the kernel dictates how \(\hat{p}(x)\) behaves, how smooth it is and how each \(x_i\) contributes to any \(x\) which we plug into \(\hat{p}(x)\). A common choice is to use standard normal Gaussians which we are also going to use in the example later. What is more, it can be shown that if \(K(x)\) is a valid PDF, i.e. satisfying, among others, \eqref{eq:ParzenWindow_PDFConstraints}, \(\hat{p}(x)\) is a valid PDF as well!
Two operations are performed in the argument of the kernel function. The kernel is shifted to the position \(x_i\) and stretched horizontally by the side length \(h\) which determines the range of influence of the kernel. Similar to before, \(h\) specifies the number of points which contribute to the bins – only that the bins are now more complicated. We don't have a clear bin-structure anymore since the bins are now implemented by the kernel functions.
In the prefactor, the whole function is scaled by \(\xfrac{1}{h \cdot N}\). As before in \eqref{eq:ParzenWindow_Histogram}, this is necessary so that the area enclosed by \(\hat{p}(x)\) equals 1 (requirement for a valid PDF). This is also intuitively clear: as more points we have in our dataset, as more we sum up and to compensate for this we need to scale-down \(\hat{p}(x)\). Likewise, as larger the bin width \(h\), as wider our kernels get and as more points they consider. In the end, we have to compensate for this as well.
We now could directly start and use this approach to retrieve a smooth PDF. However, let's apply \eqref{eq:ParzenWindow_KernelDensity} first to a small example and this is easier when we stick to uniform kernels for a moment. This does not give us a smooth function, but hopefully some insights in the approach itself. The uniform kernels have a length of 1 and are centred around the origin
\begin{equation} \label{eq:ParzenWindow_KernelUniform} K_U(x) = \begin{cases} 1, & -0.5 \leq x \leq 0.5 \\ 0, & \text{else} \\ \end{cases} \end{equation}When we want to know how this kernel behaves, we must first talk about the kernel argument \(\xfrac{x_i - x}{h}\). How does the kernel change with this argument? As mentioned before, it stretches and shifts the kernel to the position of \(x_i\). To see this, let us replace \(x\) in \(0.5 \leq x \leq 0.5\) with our kernel argument:
\begin{align*} &\phantom{\Leftrightarrow} -0.5 \leq \frac{x_i - x}{h} \leq 0.5 \\ &\Leftrightarrow -0.5 \cdot h \leq x_i - x \leq 0.5 \cdot h \\ &\Leftrightarrow -0.5 \cdot h \leq -(-x_i + x) \leq 0.5 \cdot h \\ &\Leftrightarrow 0.5 \cdot h \geq -x_i + x \geq -0.5 \cdot h \\ &\Leftrightarrow -0.5 \cdot h \leq -x_i + x \leq 0.5 \cdot h \\ &\Leftrightarrow -0.5 \cdot h + x_i \leq x \leq 0.5 \cdot h + x_i \\ \end{align*}Here, we basically moved everything except \(x\) to the borders so that we see how each side is scaled by \(h\) and shifted to the position \(x_i\). Note also that this kernel is symmetric and hence has the same absolute value on both sides. The rest of \eqref{eq:ParzenWindow_KernelDensity} is straightforward since it only involves a summation and a scaling at the end. Let's move on and apply \eqref{eq:ParzenWindow_KernelDensity} to the example values \(X\) (\eqref{eq:ParzenWindow_ExampleData}) and using \(h=2\)
\begin{align*} \hat{p}(x) &= \frac{1}{8} \left( \begin{cases} 1, & 0 \leq x \leq 2 \\ 0, & \text{else} \\ \end{cases} + \begin{cases} 1, & 0.5 \leq x \leq 2.5 \\ 0, & \text{else} \\ \end{cases} + \begin{cases} 1, & 2 \leq x \leq 4 \\ 0, & \text{else} \\ \end{cases} + \begin{cases} 1, & 4 \leq x \leq 6 \\ 0, & \text{else} \\ \end{cases} \right) \\ &\approx \frac{1}{8} \begin{cases} 1, & 0 \leq x < 0.5 \\ 2, & 0.5 \leq x < 2.5 \\ 1, & 2.5 \leq x \leq 6 \\ 0, & \text{else} \\ \end{cases} \end{align*}As you can see, each piecewise defined function is centred around a data point \(x_i\) and after the summation we end up with a step function5. It is also easy to show that \(\hat{p}(x)\) integrates indeed up to
\begin{equation*} \int_{-\infty}^{\infty} \! \hat{p}(x) \, \mathrm{d}x = \frac{1}{8} \cdot \left( 0.5 \cdot 1 + 2 \cdot 2 + 3.5 \cdot 1 \right) = 1. \end{equation*}The next plot shows our estimate \(\hat{p}(x)\) together with the previous histogram.
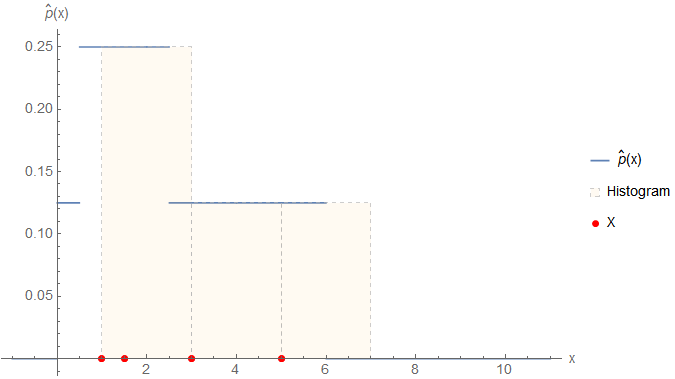
Even though the two PDFs are not identical, they are very similar in the sense that both are step functions, i.e. not smooth. This is the case because \eqref{eq:ParzenWindow_KernelDensity} inherits its properties from the underlying kernels: uniform kernels are not smooth and the same is true for \(\hat{p}(x)\).
So much for the detour to uniform kernels. Hopefully, this has helped to understand the intuition behind \eqref{eq:ParzenWindow_KernelDensity}. Things get even more interesting when we start using a more sophisticated kernel; a Gaussian kernel for instance (with mean \(\mu\) and standard deviation \(\sigma\))
\begin{equation} \label{eq:ParzenWindow_Gaussian} g(x) = \frac{1}{\sqrt{2 \pi} \sigma} \cdot e^{-\frac{\left(x - \mu\right)^2}{2 \sigma^2}}. \end{equation}More concretely, we are using standard normal distributed kernels, i.e. \(\mu=0, \sigma=1\)
\begin{equation*} K_g(x) = \frac{1}{\sqrt{2 \pi}} \cdot e^{-\frac{x^2}{2}}. \end{equation*}This kernel choice makes the Parzen estimator more complex but is also a requirement to achieve our smoothness constraint. The good thing is, though, that our recent findings remain valid. If we use this kernel in \eqref{eq:ParzenWindow_KernelDensity} with our example data \(X\) (\eqref{eq:ParzenWindow_ExampleData}), we end up with
\begin{equation} \label{eq:ParzenWindow_EstimateGaussian} \hat{p}(x) = \frac{1}{4 \sqrt{2 \pi } h} \cdot \left( e^{-\frac{1}{2 h^2} \cdot (x-5)^2}+e^{-\frac{1}{2 h^2} \cdot (x-3)^2}+e^{-\frac{1}{2h^2} \cdot (x-1.5)^2}+e^{-\frac{1}{2 h^2} \cdot (x-1)^2} \right). \end{equation}Even though the function is now composed of more terms, we can still see the individual Gaussian functions and how they are placed at the locations of the data points. The interesting thing with the standard Gaussian kernel \(K_g(x)\) is that the shift \(x_i - x\) and the parameter \(h\) correspond directly to the mean \(\mu\) and the standard deviation \(\sigma\) of the non-standard Gaussian function \(g(x)\). You can see this by comparing \eqref{eq:ParzenWindow_Gaussian} with \eqref{eq:ParzenWindow_EstimateGaussian} which basically leads to the following assignments:
\begin{align*} \mu &= x_i \\ \sigma &= h \end{align*}i.e. the Gaussian kernel is scaled by \(h\) and shifted to the position of \(x_i\). How does \(\hat{p}(x)\) now look like and what is the global effect of the side length \(h\)? You can find out in the following animation.
Note how (as before) each kernel is centred at the position of the data points and that the side length \(h\) still influences how many points are aggregated. But compared to the uniform kernels before, we don't have the clear endings of the bins anymore. It is only noticeable that the Gaussians get wider. However, this is exactly what makes our resulting function smooth and this is, after all, precisely what we wanted to achieve in the first place.
Before we move further to an example in the two-dimensional case, let us make a small detour and reach the Parzen window estimator from a different point of view: convolution.
From convolution to the Parzen window estimator
If you asked a specialist from the signal theory field about the Parzen window estimator, you would probably get a different explanation which includes the words “convolution” and “delta functions”. Even though this approach is completely different from what we have so far, the result still coheres with our previous findings. The first thing we need to do is to convert our data points to a continuous function \(s(x)\) (the input signal). We can do so by placing a Dirac delta function \(\delta(x)\) at each data point
\begin{equation*} s(x) = \delta (x-5)+\delta (x-3)+\delta (x-1.5)+\delta (x-1). \end{equation*}Then, we simply convolve our signal \(s(x)\) with the kernel we want to use
\begin{equation*} \hat{p}(x) = s(x) * \frac{1}{h \cdot N} \cdot K_g\left(\frac{x}{h}\right) = \frac{1}{4 \sqrt{2 \pi } h} \cdot \left( e^{-\frac{1}{2 h^2} \cdot (x-5)^2}+e^{-\frac{1}{2 h^2} \cdot (x-3)^2}+e^{-\frac{1}{2h^2} \cdot (x-1.5)^2}+e^{-\frac{1}{2 h^2} \cdot (x-1)^2} \right). \end{equation*}As you can see, the response is already the estimate \(\hat{p}(x)\) and the result is indeed the same as in \eqref{eq:ParzenWindow_EstimateGaussian}. Note that the shifting \(x_i - x\) is not necessary anymore since this part is already handled by the delta functions. An important aspect to mention here is the identity property of the convolution operation: if you convolve a function with the delta function, you get again the input function in return. This property applied to the kernel means
\begin{equation} \label{eq:ParzenWindow_ConvolutionIdentity} K_g(x) * \delta(x_i - x) = K_g(x_i - x) \end{equation}and that explains how the kernels are shifted to the positions of the data points. To see how the response emerges “over time”, you can check out the following animation.
Of course, the responses are also visually identical. This is not surprising since the same function is plotted. If you take the time, you can see why the resulting function looks the way it does. For example, around \(t=1.5\), the PDF \(\hat{p}(x)\) reaches its maximum. This becomes clear if you consider the kernel functions around this position: when approaching \(t=1.5\) from the left side, two Gaussians are rising (orange and green) and one is falling (blue). After \(t=1.5\) only one function is rising (green) and two are falling (blue and orange). Hence, the summed kernel responses must also decrease after \(t=1.5\).
So much for the detour to the convolution approach. It is interesting to see that both approaches lead to the same result and in essence cover the same idea (but implemented differently): use a set of kernel functions to generate a PDF which reflects the distribution of the data points. The next step is to generalize \eqref{eq:ParzenWindow_KernelDensity} to arbitrary dimensions and give an example in the two-dimensional case.
Multi-dimensional data
Extending \eqref{eq:ParzenWindow_KernelDensity} to work in arbitrary dimensions is actually pretty simple. The idea is that our bin, which we assumed so far as a structure which expands only in one dimension, is now a hypercube7 expanding to arbitrary dimensions. This results in a quad in 2D and a cube in 3D. Nevertheless, the general idea is always the same: collect all the data which falls into the hypercube, i.e. lies inside the boundaries of the hypercube. Note that this is also true if you want to calculate a histogram of higher dimensional data.
The factor \(\xfrac{1}{h}\) in \eqref{eq:ParzenWindow_KernelDensity} (or \eqref{eq:ParzenWindow_Histogram}) has compensated for the bin width so fare. When we want to use hypercubes, we must compensate by the hypervolume instead (area in 2D, volume in 3D etc.). So, the only adjustment in order to work in the \(d\)-dimensional space is to divide by \(\xfrac{1}{h^d}\) instead. This leads to the generalization of \eqref{eq:ParzenWindow_KernelDensity}:
Let \(X = \left( \fvec{x}_1, \fvec{x}_2, \ldots, \fvec{x}_N \right) \in \mathbb{R}^{N \times d}\) be the matrix containing the \(d\)-dimensional data points \(\fvec{x}_i \in \mathbb{R}^d\) (\(i\)-th row of \(X\)). Each column corresponds to a variable (or feature) and each row to an observation. Then, we can use the Parzen window estimator
\begin{equation} \label{eq:ParzenWindow_KernelDensity2D} \hat{p}(\fvec{x}) = \frac{1}{h{\color{Mulberry}^d} \cdot N} \cdot \sum_{i=1}^N K \left( \frac{\fvec{x}_i - \fvec{x}} {h} \right) \end{equation}to retrieve a valid PDF which returns the probability density for \(d\) independent variables \(\fvec{x} = \left( x_1, x_2, \ldots, x_d\right)\). The kernels \(K(x)\) have to be valid PDFs and are parametrized by the side length \(h \in \mathbb{R}^+\).
The only new parameter is the dimension \(d\). The other difference is that the independent variable \(\fvec{x} = (x_1, x_2, \ldots, x_d)\) is now a vector instead of a scalar since \(\hat{p}(\fvec{x})\) produces a multi-dimensional PDF. In the following tab pane, you can see an example in the two-dimensional case.
Did you notice that the range of \(h\) had been \([0.2;2.5]\) in the first and \([0.05;0.5]\) in the second example? You may noticed that setting \(h\) to the same value does necessarily lead to the same results. Of course, we cannot expect identical PDFs since the data points and even the dimensionality is different. However, even when we bear in mind these differences, the resulting functions are still not the same. More precisely, smaller values for \(h\) in the first example are sufficient to get a smooth function. This is because the scaling of the data is different in both cases. Hence, \(h\) should be selected whilst taking into account the scaling of the data. This is also intuitively clear: the width (or hypervolume) of the bins is spanned in the space of the data and hence inherits its scaling. It is therefore not possible to give general recommendations for the parameter \(h\). However, there are different heuristics to get estimates for this parameter8.
We have now finished our discussion about the Parzen window estimator. We started to define what a good PDF is composed of (resemble the data, smoothness and validity) and then approached the goal in two ways. One way led over histograms which are simplistic PDFs by themselves but can be extended to also fulfil the smoothness constraint. However, even this extension (the Parzen window estimator) inherits the basic behaviour and ideas from the histograms; namely the bins which collect the data and are parametrized by the side length \(h\). Depending on the kernel \(K(x)\), these bins may not have strictly defined borders. The other way led to the signal theory where we transferred our data points to a superposition of delta functions which we then simply convolved with the kernel and we saw that the two ways lead to identical results. In the last part, we generalized the approach to arbitrary dimensions and took a look at a two-dimensional example.
List of attached files:
- ParzenWindow.nb [PDF] (Mathematica notebook which contains all the one-dimensional examples and graphics)
- ParzenWindow_Example2D.nb [PDF] (Mathematica notebook with the two-dimensional example)