When analysing images, it is often desired to make the analysis scale invariant. Objects may appear in different sizes in an image either because the image resolution is different or because the distance of the object to the camera varies between a series of images. Invariance with respect to scale is a property of image processing algorithms which incorporate this observation and adjust its calculations accordingly, e.g. by making sure that a similar output is produced for two images showing the same object but in different sizes. This is not easy, but a general idea is to consider multiple scale levels of an image meaning the same image is analysed in different resolutions. Feature algorithms like SIFT implement this idea by building a (Gaussian) scale space where the original image is repeatedly blurred to achieve the behaviour of different scales. In this article, I want to talk a bit about scale spaces and what they imply.
I start by analysing what scaling in an image actually means and how we can implement it. We will see that scaling has also an influence on the area we need to consider when we try to analyse a certain structure. The goal of the first part is to make the necessity of a scale space clear and convey insights into what we need to consider when using it. The second part shows an example of how we could build a scale space by trying to cover important ideas in this field.
Why size matters and why the intrinsic resolution matters even more
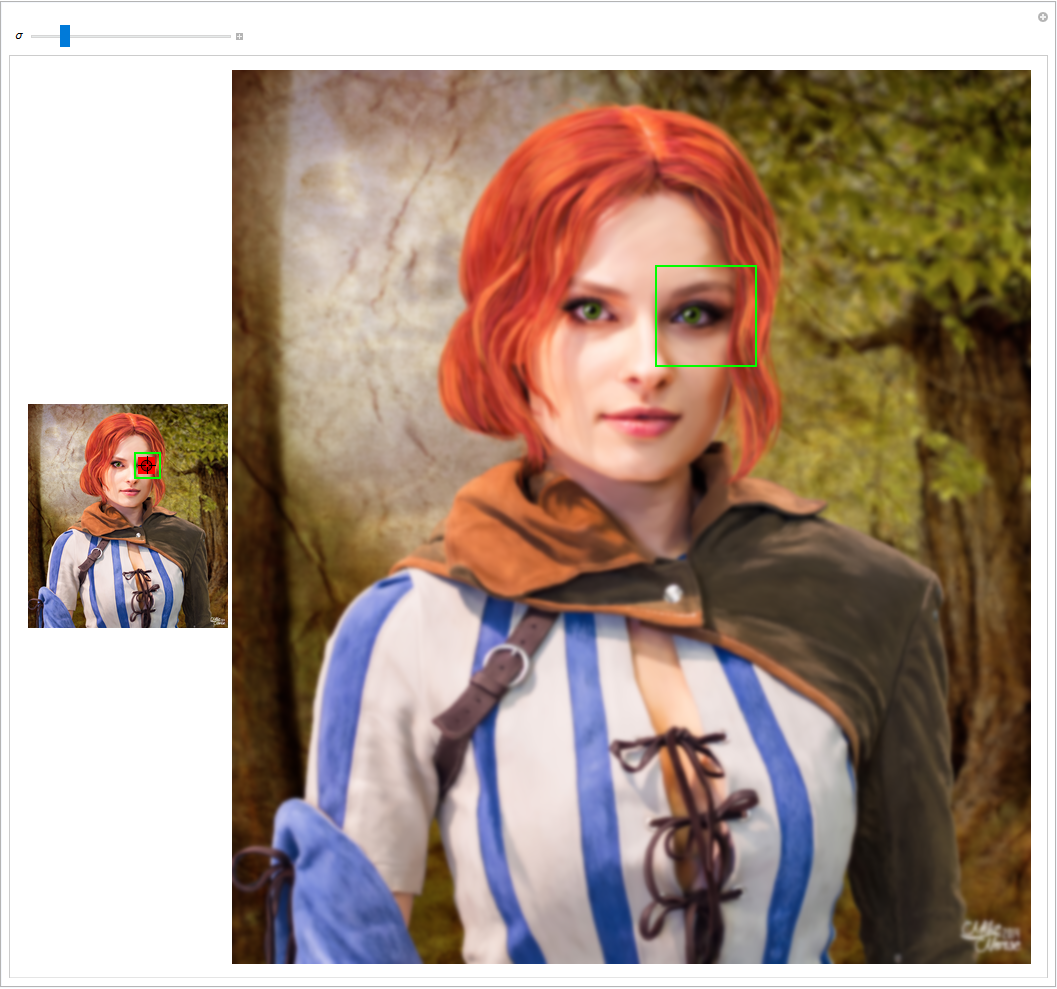
Let’s dive directly in by considering an example. The following two images show the same object but in different sizes. The original image (right) has a size of \(3866 \times 4320\) pixels (width by height) whereas the left one is scaled-down by 0.25 to the new size of \(966 \times 1079\) pixels using the nearest neighbour technique (i.e. no interpolating).


In the following, I want to analyse the local structure around the eye in more detail. If we would restrict the analysis to the mentioned rectangle of size \(100 \times 100\), the resulting image regions are very different since the rectangles extend to different parts of the image. This is not surprising since a distance of 100 px depends on the size of the image. We can say that the meaning of 100 px varies depending on the image size, i.e. it is not scale invariant.

We need to adjust the rectangle's size, obviously. Since the left image is scaled-down by \( \frac{1}{4} \), lets scale-up the right rectangle by 4, so that the new size becomes \(400 \times 400\) pixels.

Now, both rectangles cover roughly the same image region, but the original one has much more information (more details, e.g. visible in the reflection of the eye). You can also argue with the entropy here (the amount of information per area): the entropy of the left image is lower than the entropy of the right image. To achieve scale invariance, we want the entropy to be roughly the same in both image regions. Remember: we want to analyse an object regardless of its size, but when one area shows the object in much more detail then the result still varies depending on the image size.
Let’s think a little bit about the scaling operation. What does scaling mean? We decrease our image size, obviously, and that means we lose information. This is unavoidable since we use fewer pixels to describe the object, fewer pixels to describe all the beautiful details in the image (of course, this is more noticeable in the eye than in the skin – repeating pixels don’t give us more information).
The exact loss of information depends also on the reducing technique. A very easy technique would be to just sub-sample the image by removing every n-th pixel (e.g. remove every second pixel to retrieve a half-sized version of the image). A more sophisticated approach takes the surrounding pixels into account. Blurring is one way to calculate a new pixel value depending on the local neighbourhood. It also reduces information, since the neighbouring pixels are weighted which levels-out the variation of pixel differences. The kind of weighting depends on the kind of blurring. One very common way is to use Gaussian blurring for the job.
Gaussian blurring offers a very nice way to visualize the loss of information. For this, we leave our spatial domain and take a tour to the frequency domain. The Fourier transform of a Gaussian function is very special: it remains a Gaussian function. What changes is the \(\sigma\) value. The Gaussian function in the spatial domain
\begin{equation} \label{eq:GaussianScaleSpace_GaussSpatial} g_{\sigma}(x,y) = \frac{1}{2 \pi \sigma^2} \cdot e^{-\frac{x^2+y^2}{2 \sigma ^2}} \end{equation}leads to (after the Fourier transform)
\begin{equation} \label{eq:GaussianScaleSpace_GaussFrequency} G_{\sigma}(\omega_1, \omega_2) = \frac{1}{2 \pi} \cdot e^{-\frac{\left(\omega_1^2+\omega_2^2\right) \cdot \sigma^2}{2}} \end{equation}in the frequency domain. So, with increasing \(\sigma_s\) in the spatial domain, the corresponding \(\sigma_f\) in the frequency domain decreases. More precisely, the relation \begin{equation} \label{eq:GaussianScaleSpace_GaussRelationFrequency} \sigma_s = \frac{1}{\sigma_f} \end{equation} can be observed. This means a wide Gaussian curve in the spatial domain corresponds to a peaked Gaussian curve in the frequency domain. This is also visualised in the following animation.
Notice how a large \(\sigma\)-value (high blurring) results in a very small peak in the frequency domain. This gives us important insights when considering the convolution theorem: convolution in the spatial domain corresponds to multiplication in the frequency domain meaning \(g(x) * k(x)\) is the same like \((2\pi)^{\frac{n}{2}} \cdot G(\omega) \cdot K(\omega)\), with \(n\) the number of independent variables; e.g. \(2\) in the image case. So, when we blur our image (which is done by convolution) with a Gaussian function with a high \(\sigma\) value, it is the same as multiplying the image in the frequency domain with a Gaussian function with a low \(\sigma\) value. And by applying this low-pass filter (keeping only frequencies from the lower band), we remove all the high frequencies since a narrow Gaussian consists of mostly zeros outside the peak. The thing is that these high frequencies are responsible for holding all the high details in the image together. High frequencies, i.e. fast changes of intensity values, are needed to show the colour changes details usually consists of (otherwise we would not call them details but rather homogeneous areas).
Back to the example from the beginning. The original image (with increased rectangle size, i.e. \(400 \times 400 \) pixels) contains too many details compared to the reduced version, so let’s blur it with a Gaussian:

The number of details (or the entropy) is now much more similar between the two images. E.g. the stripes in the reflection of the eye are not as clearly visible anymore as before. This is exactly what we wanted to achieve. But, compared to the reduced version, the transitions are smoother, which is a direct effect of the blurring instead of a local neighbour approach.
Also note that for the right image the actual image size has not decreased, we still use the same number of pixels as before. Only the intrinsic image resolution2 changed: fewer details in the image. That is why we increased the size of the rectangle to account for the different real image resolution. If we would now analyse the two image regions, we would probably get a better result as before, since we cover the same spatial area (rectangle size) and consider roughly the same amount of details (blurring). This is precisely what we wanted to achieve for scale invariance since it allows us to analyse the same objects in images of different sizes.
So far, we created one additional scaled version of the original image (0.25 of the original size). Since I already used the term scale space before, there is indeed more. The idea is to add a third dimension to the original image which covers all possible scalings. This results in a three-dimensional function \(\hat{I}(x,y,\sigma)\) with the scaling parameter \(\sigma\) as the third dimension. It is then possible to consider (theoretically) all possible scaled version of an image. In the real world, of course, this process will be discretely sampled3. In the end, scale invariance is achieved by considering different scale levels up to a certain point and applying the used algorithms for all these scale levels (or adapt the algorithms to work directly inside the scale space, cf. the SIFT paper).
I will show an example of a scale space later. But first, summarize what we want from a scale space so that it can help us with scale invariance:
- We need to adjust the area we want to analyse to fit the current image size. This is especially important for filter operations where a filter kernel operates at each location in a local neighbourhood. The size of the neighbourhood (or the kernel size) corresponds to the size of the rectangle above. Hence, we may need to adjust the kernel size to be scale invariant. Alternatively, we stick to one kernel size but reduce the image size instead (see below).
- To consider an object at different sizes, we need different scaled versions of an image. More importantly, the intrinsic information (or the entropy) must change. We can use Gaussian blurring for this job which offers very good quality.
Before I continue to show how a scale space can be built based on these requirements, I want to take a detailed look at the scale parameter \(\sigma\) and how it behaves when the image is blurred multiple times.
A detailed look at the scale parameter \(\sigma\)
You may have wondered why I blurred the image with \(\sigma=1.936\). Actually, this is a little bit complicated. It is based on the assumption that the original image is already a blurred version of the continuous function with \(\sigma_s=0.5\) [616]4, which is somehow related to the Nyquist–Shannon sampling theorem (sampling frequency of \(\sigma_f=2\) is related to \(\sigma_s=0.5\)). Next, if we double our \(\sigma\) value, we should also double the size of the rectangle [642]. Since our rectangle is 4 times larger than the original one, we do the same with the \(\sigma\) value.
So, why \(\sigma = 1.936\) instead of \(\sigma = \sigma_s \cdot 4 = 2\)? Well, this is probably only from theoretical interest; you won’t see a difference between images blurred with \(\sigma=2\) or \(\sigma=1.936\). The reason is that we want our continuous function to be blurred with \(\sigma = 2\). The continuous function is the theoretical view of the light signals from the real world which were captured by the camera to produce the image. But we don’t have the continuous function, only the image which is a blurred version of the continuous function (with \(\sigma_s=0.5\)). So we have (\(f\) denotes the continuous function and \(I\) the discrete image function)
\begin{equation} \label{eq:GaussianScaleSpace_BlurContinuousFunction} f * g_{\sigma} = \underbrace{f * g_{\sigma_s}}_{=I} * g_{\sigma_x} = I * g_{\sigma_x} \end{equation}and this means we need to calculate the unknown \(\sigma_x\). There is a rule5 [761] which states
\begin{equation} \label{eq:GaussianScaleSpace_ScaleCombinations} \sigma = \sqrt{\sigma_s^2 + \sigma_x^2} \end{equation}which only needs to be solved by \(\sigma_x\) and that is where the mysterious value comes from
\begin{equation*} \sigma_x = \sqrt{\sigma^2 - \sigma_s^2} = \sqrt{4 - 0.25} \approx 1.936. \end{equation*}\(g_{\sigma_x}\) is therefore the kernel we need to convolve the image \(I\) with to retrieve a result which is equivalent to the continuous function blurred with \(\sigma = 2\) as stated by \eqref{eq:GaussianScaleSpace_BlurContinuousFunction}. But I agree when you say that this operation really does not change the world (it may be important in other contexts or with other values though). I should also mention that in real scenarios a base scaling for the image is defined (e.g. \(\sigma = 1.6\)) [617], which already compensates for some of the noise in the image. This blurred version of the input image is then the basis for the other calculations.
Note that \eqref{eq:GaussianScaleSpace_ScaleCombinations} applies also when the image is blurred multiple times. Blurring the image two times with a Gaussian is equivalent to one Gaussian function with a \(\sigma\) value calculated according to \eqref{eq:GaussianScaleSpace_ScaleCombinations}. This will get important when we build our scale space later.
Let's discuss the appropriate size of the rectangle a bit more. To make things easier, assume we only use squares and therefore only need to calculate a width \(w\). The idea is to connect the width with the \(\sigma\) value in such a way that the entropy inside the rectangle stays roughly constant. This means when \(\sigma\) increases \(w\) must also increase to account for the information loss which the blurring is responsible for (assuming the real resolution of the image stays the same), i.e. the loss of entropy due to the blurring is recovered by expanding the area of interest. The same logic can be applied when \(\sigma\) decreases. Of course, there must be a base width \(w_0\) (like 100 px) and the actual width is computed relative to this base width. More concretely, since the original continuous function has a base blurring of \(\sigma_s\) and we want to achieve a blurring of \(\sigma\), the appropriate width can be calculated as
\begin{equation} \label{eq:GaussianScaleSpace_RectangleSize} w = w_0 \cdot \frac{\sigma}{\sigma_s}. \end{equation}In the previous example this was
\begin{equation*} w = 100\,\text{px} \cdot \frac{2}{0.5} = 400\,\text{px}. \end{equation*}If you want to play a bit around with different rectangle sizes and scale levels, you can use the Mathematica notebook6 which I created for this purpose. There you can also move the rectangle to a different position to analyse other structures.
Building a scale space
In this section, I want to show a concrete example of a scale space. Note the word example here. There is no unique way of building a scale space but there are general ideas which I try to embed here. Also, the example presented is not used by me in practical applications, I invented it solely for educational purposes. However, it is easy to find other approaches on the web7.
First, we must talk about the scaling operation (again). Like before, I want to use Gaussian functions to repeatedly blur the image and hence build the scale space. A Gaussian offers good quality and has a nice counterpart in the frequency domain (namely itself). But it comes at the cost of performance. Blurring an image means convolving the image with a discrete kernel. The Gaussian function is by its nature continuous. Hence, we need to discretize it, e.g. by taking the function values at every integer position and put them in a kernel. When you look at the graph from the animation again, you will see that this does not result in nice numbers. We definitively need floating operations for the job and this will be computationally intensive. Remember, that blurring is an essential operation when we want to change the intrinsic resolution of an image and hence the underlying operation should be fast.
Luckily, there are other filters which approximate the behaviour of a Gaussian-like binomial filters which are commonly used. They are extracted from Pascal's triangle where each row in the triangle can be used as a filter with a specific variance. Since the triangle is built only by addition of integers, the resulting filters will also consist of integers. This increases our computational efficiency.
Here, I want to approximate a Gaussian with \(\sigma=1\) since this makes the calculations later easier. The corresponding binomial filter \(B_n\) to use in this case is extracted from the row \(n=4\) and is defined as filter as8
\begin{equation*} B_4 = \frac{1}{16} \cdot \left( 1, 4, 6, 4, 1 \right)^T. \end{equation*}Note the prefactor which makes sure that the filter weights up to 1 and can be applied at the end of the convolution operation. The good thing about binomial filters is that they fit very well to a Gaussian function like the following figure depicts.
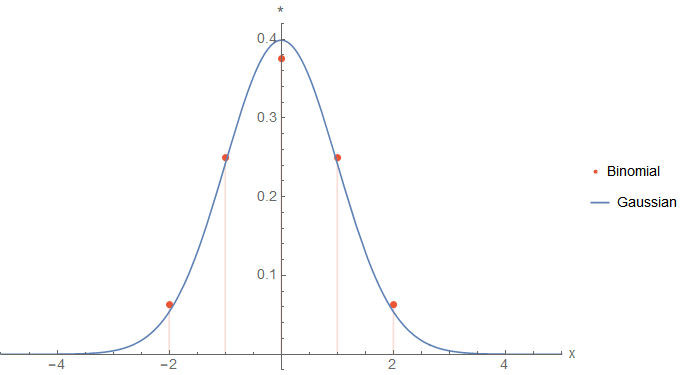
As you can see, even though we have only five integer values, the Gaussian is very well approximated. Other rows from Pascal's triangle have similar behaviour but with different \(\sigma\)-values. To apply the filter on images (which requires a 2D-filter), separation can be used. But it is also possible to expand the vector to a matrix via the outer product:
\begin{equation*} B_4^T \cdot B_4 = \frac{1}{256} \cdot \left( \begin{array}{ccccc} 1 & 4 & 6 & 4 & 1 \\ 4 & 16 & 24 & 16 & 4 \\ 6 & 24 & 36 & 24 & 6 \\ 4 & 16 & 24 & 16 & 4 \\ 1 & 4 & 6 & 4 & 1 \\ \end{array} \right) \end{equation*}After the question of the filter kernel to use is now solved, we should start with the discussion of the scale space. It is very common to build a scale pyramid like shown in the following figure.
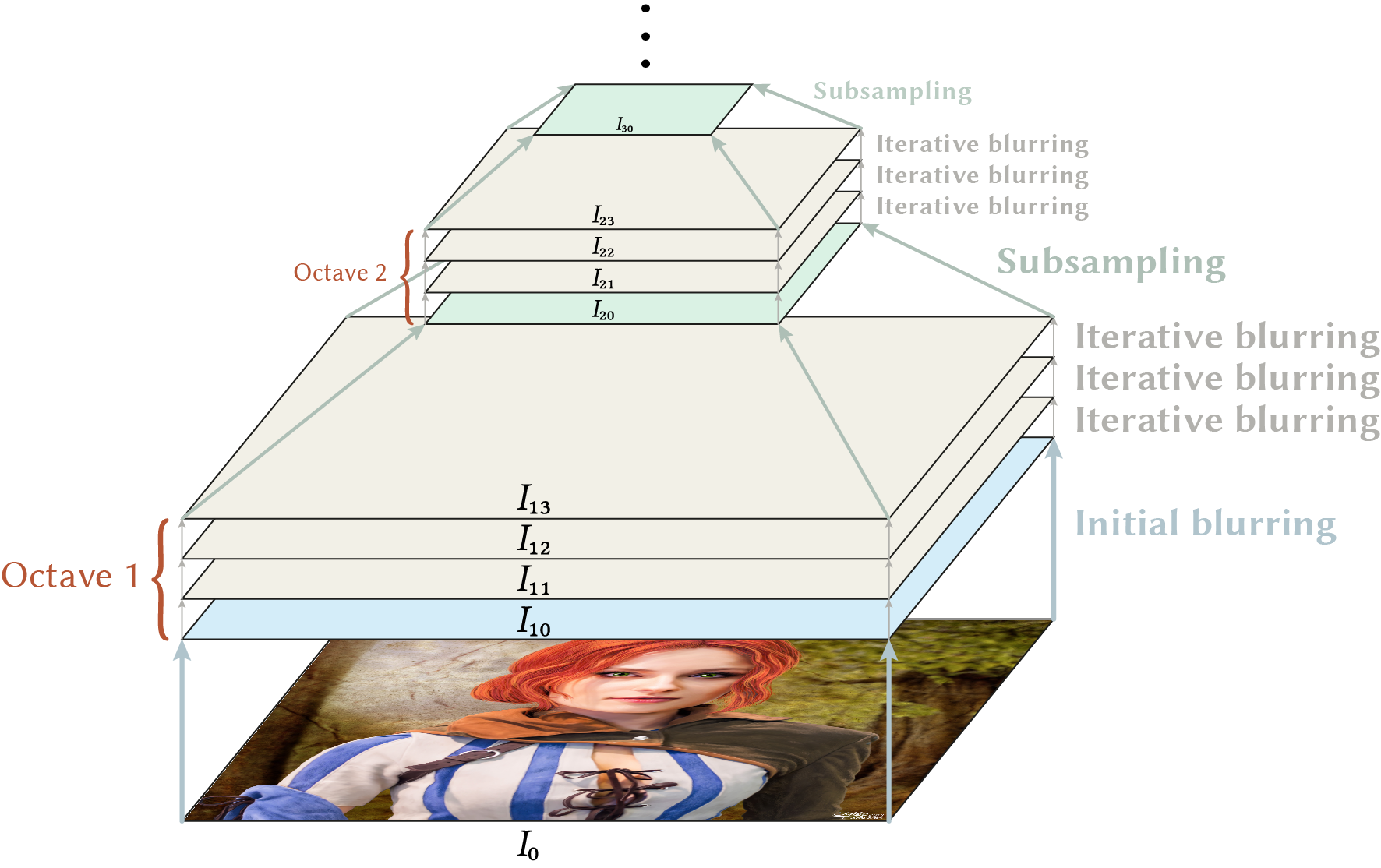
As mentioned before, the first step is to apply a base scaling to the input image. This already compensates for noise which is usually present in images produced by a camera. Then, the image is repeatedly blurred with our binomial filter until the scaling doubled. This is the moment where we have blurred and hence reduced the intrinsic resolution of the image so much that also the real resolution can be reduced as well without loss of information. This is done by subsampling, e.g. by removing every second pixel, effectively halving the image size. The idea is that the reduced version contains the same information: every structure and change in intensity values present before the subsampling is also present afterwards but described with fewer pixels. The frequency domain does also gives us insights here. According to \eqref{eq:GaussianScaleSpace_GaussRelationFrequency}, when we increase the scaling by a factor of \(\sigma_s = 2\), we multiply our signal with \(\sigma_f = 0.5\) in the frequency domain which means that most of the frequencies in the upper half are removed. Finally, we introduce the notion of an octave, which groups all images with the same size together.
Two benefits arise from the subsampling process. Most obvious is the performance increase. Usually, we build a scale space to do something with it in the next step and it is e.g. much faster to apply derivative filters to a scale pyramid where the levels decrease in size instead of a scale space where all levels have the same size as the input image. The benefit is quite huge since with each subsampling process the total number of pixels is reduced by 0.25 (both the width and height are reduced by 0.5).
But there is also another advantage. Remember that we needed to adjust the size of the rectangle when we wanted to analyse the same content at different sizes. For the derivative filters, this would mean that we need to increase its kernel size as we increase the blurring. Imagine a tiny \(3 \times 3\) filter applied to all levels of the same size. There is no way to capture larger image structures with this approach. But due to the subsampling, this problem is implicitly attenuated. When the image size increases, our \(3 \times 3\) filter automatically works on a larger local neighbourhood. Of course, we still need different filter sizes for the levels inside each octave but we can re-use the filters across octaves (e.g. the same filter can be applied to levels \(I_{11}\) and \(I_{21}\)). Note that this holds also true for the binomial filters used to build the scale pyramid itself. In our example, we only need three binomial filters (not counting the initial blurring) to build the complete pyramid and when we apply an iterative scheme we only need one!9.
To understand the build process of the scale pyramid better, let us apply it to a small one-dimensional input signal
\begin{equation} \label{eq:GaussianScaleSpace_ExampleData} \fvec{u}_0 = \left( 1, 3, 1, 5, 11, 2, 8, 4, 4 \right)^T. \end{equation}The following animation shows the steps for two octaves of the build process.
Take a look at step 5 visualizing the subsampling process which selects every second value for removal. When you take a closer look which values are to be removed, you see that they don't convey utterly important information. They merely lie in the interpolation between two other values (more or less). This shows that the subsampling is indeed justified and we don't lose too much information when we do it. The same is true for step 10 but not so much for the intermediate blurring steps. For example, we could not recover the shape defined by the signal if we subsampled already in step 7 (the value at point 4 is a bit above the interpolation line between point 3 and 5). The build process of the scale pyramid is also summarized in the table below.
| Level \(i\) | Octave | Step | Operation | Scale \(\sigma_i\) |
|---|---|---|---|---|
| 0 | 0 | Input image | \(\fvec{u}_{0}\) | \(0.5\) |
| 1 | 1 | Initial blurring | \(\fvec{u}_{10} = \fvec{u}_{0} * G_{\sigma_b}\) | \(1\) |
| 2 | 1 | Iterative blurring | \(\fvec{u}_{11} = \fvec{u}_{10} * B_4\) | \(\sqrt{2} = \sqrt{1^2 + 1^2}\) |
| 3 | 1 | Iterative blurring | \(\fvec{u}_{12} = \fvec{u}_{11} * B_4\) | \(\sqrt{3} = \sqrt{(\sqrt{2})^2 + 1^2}\) |
| 4 | 1 | Iterative blurring | \(\fvec{u}_{13} = \fvec{u}_{12} * B_4\) | \(2 = \sqrt{(\sqrt{3})^2 + 1^2}\) |
| 5 | 2 | Subsampling | \(\fvec{u}_{20} = \operatorname{sample}(\fvec{u}_{13})\) | \(2\) |
| 6 | 2 | Iterative blurring | \(\fvec{u}_{21} = \fvec{u}_{20} * B_4\) | \(\sqrt{8} = \sqrt{2^2 + 2^2}\) |
| 7 | 2 | Iterative blurring | \(\fvec{u}_{22} = \fvec{u}_{21} * B_4\) | \(\sqrt{12} = \sqrt{(\sqrt{8})^2 + 2^2}\) |
| 8 | 2 | Iterative blurring | \(\fvec{u}_{23} = \fvec{u}_{22} * B_4\) | \(4 = \sqrt{(\sqrt{12})^2 + 2^2}\) |
| 9 | 2 | Subsampling | \(\fvec{u}_{30} = \operatorname{sample}(\fvec{u}_{23})\) | \(4\) |
I think only the last column may be a bit confusing. What I wanted to show is the scaling in the respective layer, i.e. the amount of blurring which has been applied to the image so far. As mentioned before, this requires, being a stickler, the underlying continuous function which we don't know but where it is assumed that \(\fvec{u}_0\) is a blurred version of it (with \(\sigma_s = 0.5\)). But this only affects the initial blurring which I deliberately chose so that we reach a scale of \(\sigma_1 = 1\) in the first level. This part is not too important, though. However, the other calculations are important. Essentially, each parameter is calculated via \eqref{eq:GaussianScaleSpace_ScaleCombinations} with the scale parameter from the previous level (left operand) and the new increase in scaling introduced by the binomial filter (right operand). The left operand is just passed over from one level to the next and the right operand is identical in each octave. This is the case because I only use \(B_4\) as blurring operator. Other scale pyramids may differ in this point. Whenever the scale parameter doubled, the signal is subsampled10.
Did you notice that the scale parameter for the binomial filter doubled as well? It is \(\sigma_1 = 1\) in the first and \(\sigma_2 = 2\) in the second octave. This is due to the subsampling done before and related to the implicit increase of local neighbourhood which the subsampling process introduces. Since the same filter now works on a broader range of values we have effectively doubled its standard deviation. This effect is also visible in the animation above. The size of the Gaussian function stays the same when you move e.g. from step 5 to step 6. But the number of values affected by the Gaussian are much larger in step 6 (all actually) than in step 5. You can also think this way: suppose you applied the Gaussian as noted in step 6. Now, you want to achieve the same result but rather applying a Gaussian directly to step 4 (i.e. skipping the subsampling step). How would you need to change your Gaussian? Precisely, you need to double its width (or in a more mathematically term: double its standard deviation) in order to include the same points in your computation as in step 6.
We have now discussed how different scalings for an image can be achieved and why we may need to adjust the size of the local neighbourhood when analysing the image structure in different scale levels. We have seen how the frequency domain can help us to understand basic concepts and we analysed the scale parameter in more detail. Also, the question of how such a scale space can be built is answered in terms of a scale pyramid.
Ok, this sounds all great, but wait, was the intention not to analyse the same object which appears in different sizes in different images? How is this job done and how precisely does the scale space help us with that? Well, it is hard to answer these questions without also talking about a concrete feature detector. Usually, we have a detector which operates in our scale pyramid and analyses the image structure in each level. The detector performs some kind of measurement and calculates a function value at each 3D position (\(x, y\) and \(\sigma\)). Normally, we need to maximize the function and this can e.g. be done across all scale levels. But this depends highly on the feature detector in use. You are maybe interested in reading my article about the Hessian feature detector if you want to know more about this topic.
List of attached files:
- GaussianScaleSpace_TrissPSDFiles.7z (Archive containing the .psd files I used to create the images with the blue rectangle)
- GaussianScaleSpace_FrequencyDomain.nb [PDF] (Mathematica notebook to visualize the transformation of the Gaussian function to the frequency domain)
- GaussianScaleSpace_Scalings.nb [PDF] (Mathematica notebook to control the different scalings and to move the rectangle)
- GaussianScaleSpace_Binomial.nb [PDF] (Mathematica notebook used to create the figure for the binomial distribution)
- GaussianScaleSpace_BuildPyramid.nb [PDF] (Mathematica notebook with the build steps of the scale pyramid for the example data in \eqref{eq:GaussianScaleSpace_ExampleData})